Batch Jobs
STRM Privacy offers support for batch processing. This quickstart helps you to get started with Batch Jobs. To read more about the background for batch data pipelines, go here.
Prefer to look at the example notebook directly? Find it here.
Create a STRM Privacy batch mode pipeline
With batch mode, you can set up data routines that, based on the data contract, grab data from a bucket, transform it according to a data contract and subsequently pick it up for downstream processing.
This is a powerful way to quickly set up data pipelines to feed applications that process or need sensitive data in batch routines without the overhead. In the real-world, this means you align on the privacy implications with your security and/or legal counterparts first, and because privacy comes by design and is encoded into the pipeline and data itself, you can just go ahead and use it.
This saves you a lot of trips to legal desks, and so improves your workflow considerably.
Quickstart outline
The following steps will be covered in this quickstart:
- Create a data connection to retrieve and store the data
- Define the data contract your data adheres to.
- Define a batch job in the CLI
- Generate some data for demo purposes
- Explore the transformed data for downstream consumption
Creating a data connector
First create a data-connector of the desired kind.
Define the data contract
The next step is to instruct STRM Privacy what your data looks like. This is done in the data contract, which combines the data shape (your fields) with the privacy implications. In this quickstart, the privacy demo data contract is used:
- Data Contract (schema shown separately for brevity)
- Schema Definition (Avro representation)
View this data contract with the CLI
using: strm get data-contract strmprivacy/example/1.3.0 -ojson
{
"dataContract": {
"id": "44cc99df-04f1-4e42-9345-28151b1139d0",
"ref": { "handle": "strmprivacy", "name": "example", "version": "1.3.0" },
"state": "ACTIVE",
"isPublic": true,
"keyField": "consistentValue",
"piiFields": {
"consistentValue": 2,
"someSensitiveValue": 3,
"uniqueIdentifier": 1
},
"validations": [ { "field": "consistentValue", "type": "regex", "value": "^.+$" } ],
"metadata": { ... omitted ... },
"schema": {
"ref": { "handle": "strmprivacy", "name": "example", "version": "1.3.0", "schemaType": "AVRO" },
"state": "ACTIVE",
"isPublic": true,
"definition": ... shown in separate tab for brevity ...,
"fingerprint": "6093265390869578999",
"metadata": { ... omitted ... },
"simpleSchema": {},
"id": "44cc99df-04f1-4e42-9345-28151b1139d0"
},
"projectId": "d995bd01-22ea-458b-a184-4fac5ba48535"
},
"checksum": "5321256876911080621"
}
View this schema definition with the CLI
using: strm get data-contract strmprivacy/example/1.3.0 -ojson | jq '.dataContract.schema.definition | fromjson'
{
"type": "record",
"name": "DemoEvent",
"namespace": "io.strmprivacy.schemas.demo.v1",
"fields": [
{
"name": "strmMeta",
"type": {
"type": "record",
"name": "StrmMeta",
"fields": [
{ "name": "eventContractRef", "type": "string" },
{ "name": "nonce", "type": [ "null", "int" ], "default": null },
{ "name": "timestamp", "type": [ "null", "long" ], "default": null },
{ "name": "keyLink", "type": [ "null", "string" ], "default": null },
{ "name": "billingId", "type": [ "null", "string" ], "default": null },
{ "name": "consentLevels", "type": { "type": "array", "items": "int" } }
]
}
},
{
"name": "uniqueIdentifier", "type": [ "null", "string" ], "default": null,
"doc": "any value. For illustration purposes: use a value that is consistent over time like a customer or device ID."
},
{
"name": "consistentValue", "type": "string",
"doc": "any value. For illustration purposes: use a value that is consistent over a limited period like a session."
},
{
"name": "someSensitiveValue", "type": [ "null", "string" ], "default": null,
"doc": "any value. For illustration purposes: use a value that could identify a user over time based on behavior, like browsing behavior (e.g. urls)."
},
{
"name": "notSensitiveValue", "type": [ "null", "string" ], "default": null,
"doc": "any value. For illustration purposes: use a value that is not sensitive at all, like the rank of an item in a set."
}
]
}
You can use an existing data contract or create your own. Refer to this blog on creating data contracts. Furthermore, you can also use Simple Schemas, a much easier way to define your data shape than the underlying Avro serialization schema.
Define a batch job via the CLI
With the data connection and contract defined, the batch job itself can be defined. Batch jobs can be defined by providing a config JSON to the CLI. The reference can be found here.
$ strm create batch-job --help
Create a Batch Job
Usage:
strm create batch-job [flags]
Flags:
-F, --file string The path to the JSON file containing the batch job configuration
-h, --help help for batch-job
The JSON simply details which data-connector to use, what contract to apply and how to write the data back. We are working to include GCP Storage, a visual interface and even a file upload in follow-on releases.
Configure your editor (VS Code, IntelliJ) to validate the Batch Job JSON definition against the JSON Schema.
Indicate the data subject consent field
For each record (row) processed by a batch job, the data subject (data owner) may or may not consent with their data being used for certain purposes. In other words, the legal ground under which the data was collected may differ per record. In streaming pipelines, the consent is provided by you and embedded in the metadata of each event. Similarly, for batch jobs, you need to indicate which field in your data contains the legal ground per row. This field does not necessarily need to be defined in your data contract.
In the definition file you need to set these three values:
- what the default legal ground (consent level) is
- the field that contains the legal ground in your data
- how each of field's values map to consent levels
Here, consent levels are integer values referring to the respective purposes as defined in your purpose map.
About the default consent: It's safest to keep this to the integer value 0. It just means the data was collected under the most basic consent or legal ground you use.
{
// partial excerpt
"consent": {
"default_consent_levels": [ 0 ],
"consent_level_extractor": {
"field": "the field that indicates collection ground",
"field_patterns": {
"example, like legitimate interest": {
"consent_levels": [ 1 ]
},
"example, like marketing": {
"consent_levels": [ 2 ]
}
}
}
}
// partial excerpt
}
An example of the full definition file is included in the demo notebook. Just swap the example values for your own data-connector names and preferred buckets.
Indicate the timestamp config
An important part of data that is processed in batch, is the time that belongs to an individual record in the data. This can be the time this data was recorded (i.e. the event time equivalent for streaming data), or the time that this data was processed. Regardless of the meaning, it is required to have a field in the CSV data that represents a date and time. As can be seen in the Batch Job reference, the EncryptionConfig requires a TimestampConfig. The TimestampConfig defines how data is encrypted with respect to time. The privacy algorithm we use, uses the concept of time to determine whether the same encryption key or a new one should be used.
In the TimestampConfig, a format field defines the pattern that is used
to parse the date and time that is specified in the time field (denoted by field in the TimestampConfig). To test the
pattern, we advise to use the following tool. Keep a reference
to the patterns open as well.
Define the derived data
The next step is to define the derived data - the privacy-transformed output. Just think of this as a folder on a disk that contains data that is ready for a specific purpose (like, in the example below, training a recommender).
First, let's dive a bit deeper into how transformations are applied. In this quickstart, we'll focus on a specific derived stream - in real-world applications you would probably have many different purposes and so a bunch of different derived streams.
Intermezzo: Privacy-transforming your data
Based on the data contract, data is processed and transformed in your batches. The level of privacy that can be achieved depends on the format of your source data.
A temporal (i.e. time-based) field in your data is used to achieve a fast but powerful way to apply the necessary transformations (through
the keyField in the data contract) via encryption. It is therefore important to understand that data is
pseudonimized at best, unless you have multiple rows per user that are closely spaced in time (like separated clicks or
url hits with context data).
We plan to extend the privacy transforms, but as we expand batch mode further this is currently an important limitation. In streaming mode, you usually have separate but closely spaced data points (e.g. events over multiple days).
So are you planning to use batch mode for e.g. user profile info, where every row is just one user? That won't get you anonymized data currently.
A real-world use case for derived data: masking for recommenders
Imagine you have a batch job with clickstream data you plan to use to train or evaluate a recommender system.
Your data includes a PII field that you do not want or are not allowed to reveal, while you do need it for your data analysis. Recommendations are highly personal and therefore require linking previous behaviour (orders, movies etc.) to the same user.
The only "personality dimension" a basic recommender really needs is to know what was the same user. They do not necessarily need to know who was the underlying customer. This is where masking comes in.
By masking a field, the actual value (e.g. the customer id) is replaced with a hash, allowing to link multiple data points to a single user, without revealing personal information. This can be done with derived streams.
In the snippet below, you will find the derived_data configuration of the batch-job. This configuration shows the
data-connector to read from, the file to write to, and the allowed consent levels (purposes that should be decrypted).
The consent level type is deprecated and should typically be set to GRANULAR, meaning that each desired purpose should
be listed explicitly under the consent levels, and each record should explicitly specify consent for each corresponding
purpose as well. Here, CUMULATIVE means that a consent for purpose 2 will include consent for purpose 1 as well.
Finally, the snippet also shows the masked_fields. Within the data contract block
"databert-handle/batch_job_public/1.0.1"{ ... } you can see the column names or field_patterns of the fields to
mask.
{
// partial excerpt
"derived_data": [
{
"target": {
"data_connector_ref": {
"billing_id": "your_billing_id",
"name": "databert-demo"
},
"data_type": {
"csv": {
"charset": "UTF-8"
}
},
"file_name": "databert-demo-derived.csv"
},
"consent_levels": [
2
],
"consent_level_type": "CUMULATIVE",
"masked_fields": {
"field_patterns": {
"databert-handle/batch_job_public/1.0.0": {
"field_patterns": [
"Email",
"UserName"
]
}
}
}
}
]
// partial excerpt
}
Generate the batch data
In a batch job, data is read, transformed and returned as soon as new files are found inside the bucket.
To simulate a data routine you already have or plan to set up, the example notebook includes a
DataGenerator class that simulates some random user data (when we say random, we really mean "nonsensical"). Apart
from session, user and meta (like a timestamp) fields you will recognize the PrivacyPlane as the consent field in step
3.1 above.
Clone/fork/download the notebook and add/replace your own credentials in the AwsProperties() class
and s3.json to quickly prepare a demo pipeline of your own.
Explore privacy-transformed data
The data shape and privacy implications (the data contract) are now defined, the batch job is defined, a
derived stream with masking applied is defined, and some example data is generated.
Next, let's explore what happens to the data based on (1) the data contract and (2) derived stream we defined.
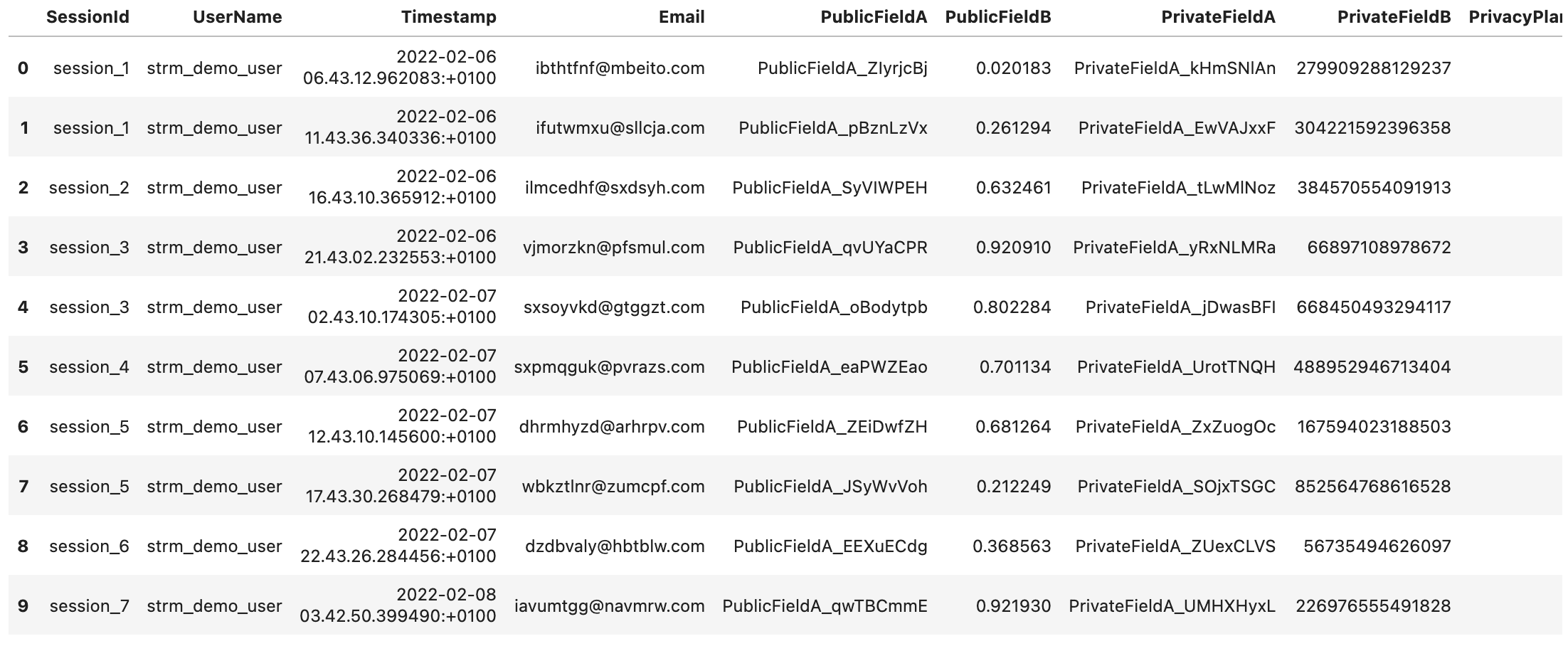
Input data
The input data coming from the DataGenerator class that acts as input looks as follows:
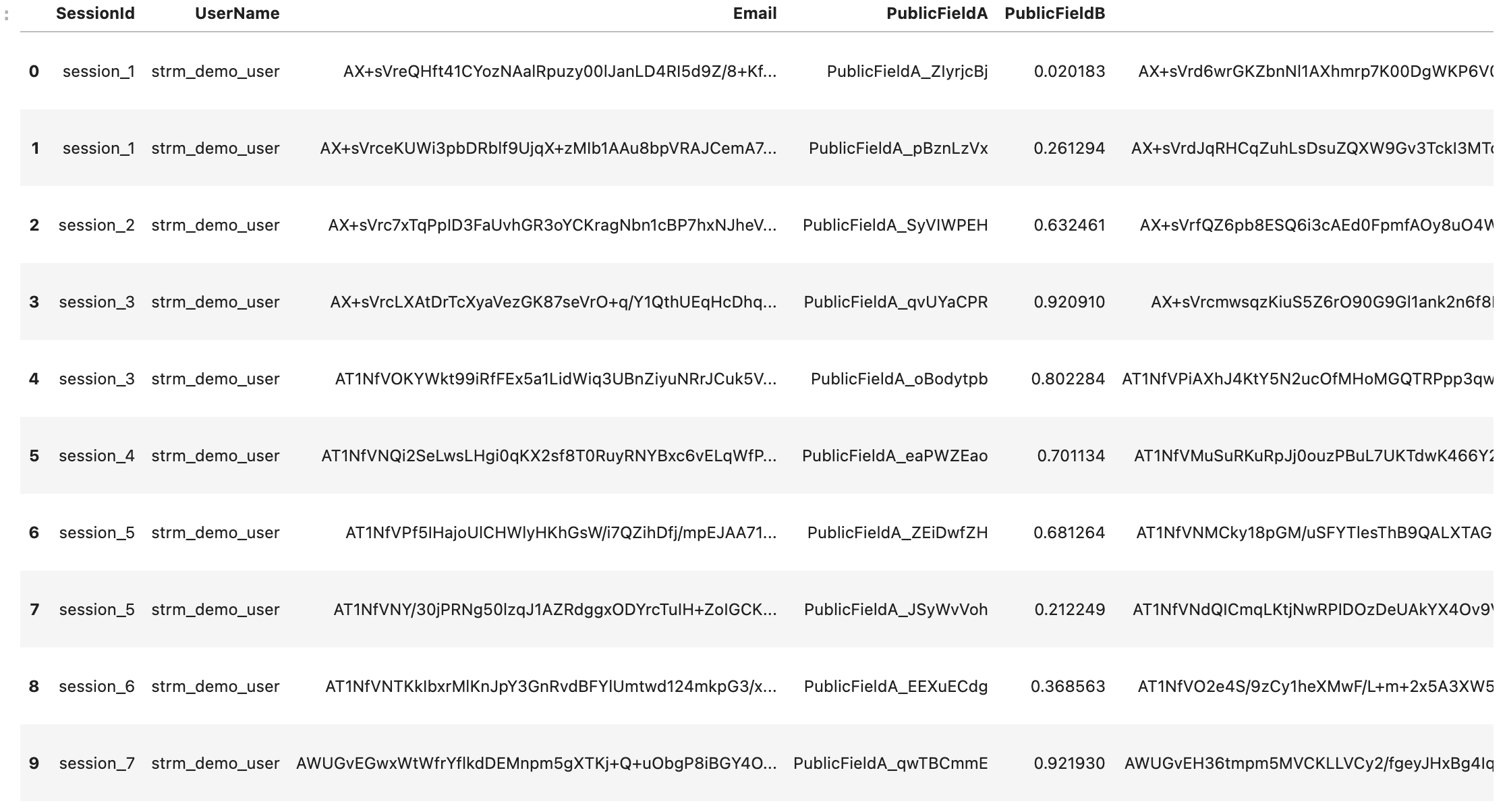
Encrypted data
The next step is to look at the data that is just encrypted (per field).
Basically, all connections that might exist between rows are destroyed here: the pii-fields Email,
PrivateFieldA and PrivateFieldB, set in the data contract, are encrypted.
Derived Data
It becomes more interesting looking at the derived data (as defined by the derived stream above). Remember, the goal was to apply masking instead of destroying any connection between rows that might exist.
Per the batch job configuration, the derived data is allowed to contain entries with a consent level of 2 or higher. From the
input data it is known that there are 3 entries with a consent level of 2, which correspond to the three outputs below. In
the table below, you can also see that the values for UserName and Email are hashed. This corresponds to the
field_patterns that have been set in de masked_fields section of the data contract for derived_data. The username
has been masked, but the hashed username is consistent over all rows. The Email field is different for every entry and
therefore the hashed field is too.
Records that did not include consent for purpose 2 have been excluded from the derived data.

Example notebook
To quickly see for yourself how Batch Mode works, copy or clone the example notebook from GitHub with your own S3 and STRM Privacy credentials and explore the data. It also includes the batch job definition file.
Wrapping up
So, to illustrate how to create batch jobs with privacy transformations, the following steps have been covered:
- We created a data connection to retrieve and store the data
- Defined the data contract your data adheres to.
- We defined a batch job in the CLI
- Generated some data for demo purposes
- Explore the transformed data for downstream consumption