Architecture
This section shows a high level architecture of STRM Privacy. It shows how data is processed, before it is exposed to an application consuming the data.
Overview
When sending data to, or receiving data from STRM Privacy, your
application must identify itself using client credentials. These
credentials are provided through the Console or via the
strm command line interface.
All events that are sent to STRM Privacy (regardless of deployment mode) have schema reference (provided through an HTTP header) that defines the structure and contents of the event.
The STRM Privacy Event Gateway will verify that the data:
...is of the correct serialization format, as specified in schema reference
...is a valid serialized message
...complies to the pre-defined validation rules, as specified in the Data Contract (the contract reference is embedded in the mandatory
strmMetasection of the event)
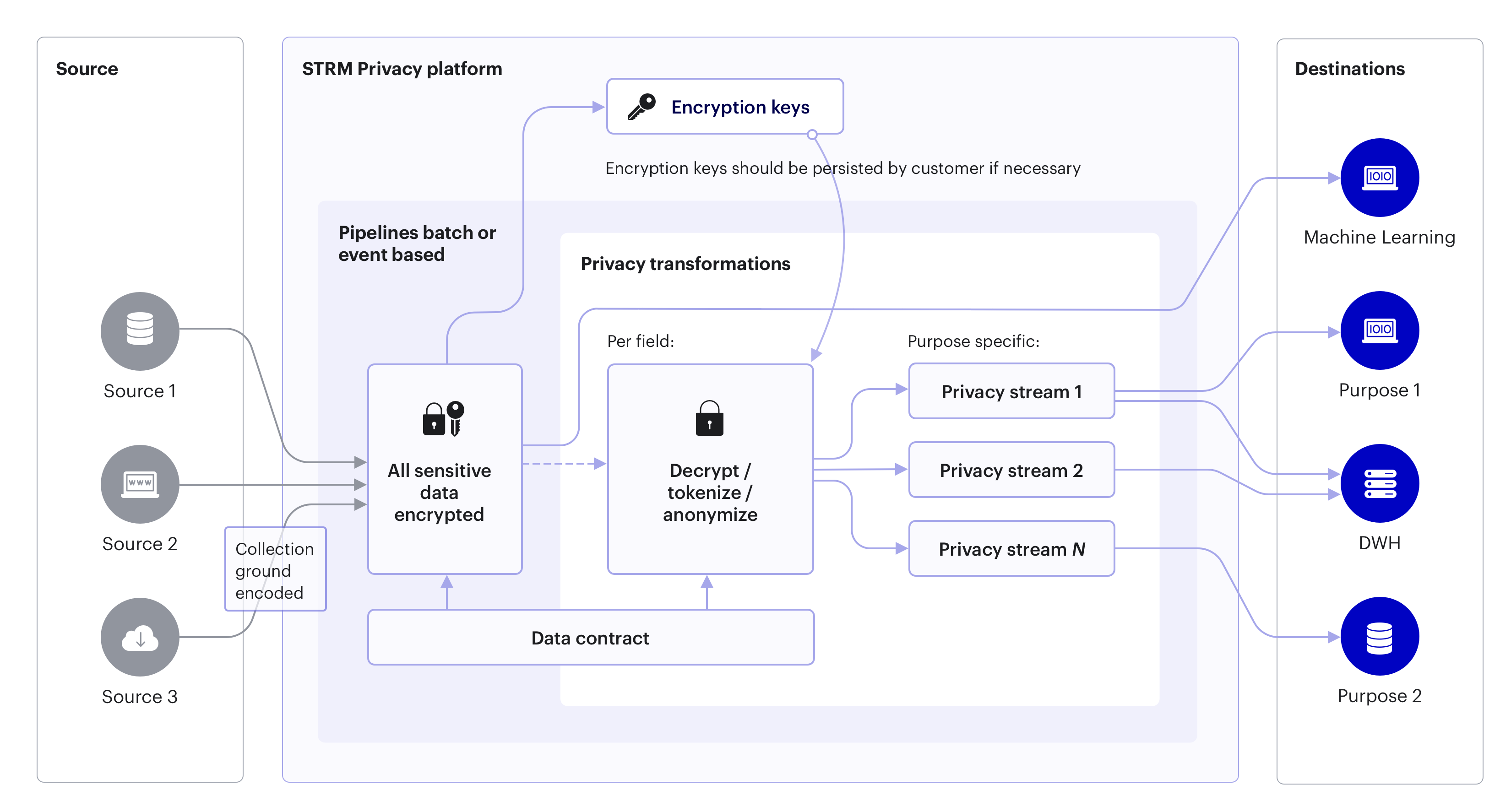
Upon accepting an event, the Event Gateway will use the Encrypter to
encrypt all defined Personal data and PII
attributes of the event. Which fields are sensitive (personal) data is defined in the data
contract. The
contract can consist of attributes related to different purposes, but all of them are
encrypted with the same encryption key that is linked to the keyField.
You can create decrypted streams that contain a subset of the encrypted stream (more specifically, only the events of data subjects that provided consent for the desired purposes), with only those Personal Data fields decrypted that you have requested. It is not required to create decrypted streams.
The algorithm is as follows:
we define a derived stream where for example we request to receive events that provide a processing basis for purposes 1, 3 and 8.
the decrypter will inspect every event, and will ignore all events that don’t have consent for at least these 3 purposes set in the
strmMeta.consentLevels.the events that are accepted by the decrypter will then be partially decrypted; only the encrypted data fields for purposes 1, 3 and 8 will be decrypted. This means that assuming a data subject has given consent for more than these purposes, fields related to other purposes will not be decrypted. This is the mechanism that STRM Privacy uses to adhere to article 6 of the GDPR. A data processing unit in a company receives only those events that the data subject has consented to, with only those Personal Data attributes it needs.
Outputs
STRM Privacy provides multiple ways to output data. Read more on exporting data here.